この記事では、Scala 3用のロギングライブラリであるScribeについて、以下のことを説明する(順不同)。
- インストール方法と基礎的な使い方
- 従来のロギングライブラリとの思想的な違いと優位性
- Scribeの構造
- そしてこれを利用した発展的な使い方
あらすじ
最近Scalaで新規に業務コードを書くことがあり、その設計と実装の中でロギングシステムについて考える機会があった。その時はとりあえずでLogbackを採用することにしたけれど、Scribeというロギングライブラリがあることを後日知った。
コードをあらかた読んだけれどとても平易で、利便性がとても高いライブラリだということを知った。しかしながらScribeはまだあまりドキュメントが充実しておらず、日本語資料はもっと足りていない。そこで、内部構造をある程度読んだ自分がScribeについて紹介する記事を書くことで、みんなにもこのライブラリを知ってもらおうと思う。きっと、他のライブラリを捨ててScribeに移行したくなるはずだ。
なぜScribeなのか、なぜ他のロギングライブラリではないのか
Scribeの使い方についての説明とは別に、なぜScribeが必要とされたのかについても触れておく。この節を読まなくてもScribeを使うことはできる。
ScribeはScalaで利用されてきたロギングライブラリが抱えていた課題を、別のアプローチを取ることで解消している。これについてこれから詳しく述べる。
従来のロギングライブラリの課題
Scribeは、以下のような課題を認識して開発された。
現行のScalaにおけるロギングライブラリはほとんどJavaのロギングライブラリのラッパーである
これまでScalaアプリケーションで使われてきたロギングライブラリは、例えばLogbackなどのJava製ロギングライブラリをそのまま使うか、scala-loggingのようなラッパーライブラリを利用してJava製ロギングライブラリを呼び出していた。 このためScala的な書き方があまりできず、Javaのしきたりに沿ったコードを書くことを強制される局面が出てしまう。
またこれに加えて、次に述べる様々な問題が発生する。
Scala.js / Scala Nativeへの非対応
Java製ロギングライブラリを利用することにより、JVMへの依存が生じてしまう。Scala.jsやScala NativeはScalaのコードをトランスパイルする機構であるため、プロジェクトがJavaライブラリに依存している状況では利用困難になる。この事はプロジェクトのポータビリティを阻害してしまう。
追加の依存性
Java製ロギングライブラリを利用することにより、沢山の依存性を導入する可能性がある。例として、アプリケーションコードでは全く利用しないJacksonなどのライブラリへの依存が発生したりする。この点は本来受忍しなくてもよかったセキュリティ上のリスクやアーティファクトサイズの拡大を招いてしまう。
パフォーマンス上の問題
多くのライブラリにおいて、ログタイミングの行数やファイル名を取得する処理は非常にコストを発生させる。これがパフォーマンス上のボトルネックとなり、パフォーマンスのためにロギングを諦めなければならないケースを発生させる。
設定の困難さ
例えばLogbackを設定するにはlogback.xmlを設定するか、手で各種のConfigulatorを作成しなければならない。周知の通り、Java製ロギングライブラリの設定ファイルを書くためには非常な努力を必要とする。また、実行中にパラメータや環境変数などに応じて設定を動的に変更したり、一部の挙動を変更するためにボイラープレートを書かなければならない。
Scribeがとるアプローチ
Scribeは前述した課題を以下のように解決し、使いやすいロギングを提供している。
Pure Scala
ScribeはScalaのみで記述されており、Java系ライブラリへの依存を持たない。このため、Scala.jsやScala Nativeに標準で対応する。
また、Pure Scalaであることにより、記法もScala的な書き方で統一されている。とても開発者体験が良いと思う。
コンパイル時に必要な情報を集める
ScribeはScala 3の改良されたマクロ機構を利用し、実行時のコストを極限まで下げることでパフォーマンス上の問題に対処している。コンパイル時に行数やファイル名などの情報が確定するため、行数を出力しても追加のコストを支払わなくてもよい。この仕組みによりパフォーマンスはきわめて良い。
また、これによりロガー呼び出し元のクラスを汚すこともない。
平易でプログラマブルな設定システム
Scribeは設定ファイル機構を一切提供せず、ロガーの追加設定は実行時に任意のタイミングで行うことができる。またこの機構はScala的な書き方で利用できるため、一度メカニズムを理解すれば容易にカスタマイズできる。
非同期ライブラリへの対応
ScribeはCats Effectといった非同期ライブラリへのサポートを行っているため、スレッドをブロックするなどの副作用を生じることなくロギングを行える。このためパフォーマンスクリティカルな並行処理でも容易にロギングが可能だ。
Scribeの特長
ここでは、特筆すべきScribeの特長についていくつか説明する。どれも現代的で魅力的だと思う。
ゼロコンフィグ
Scribeは一切のコンフィギュレーションなしに動作する(依存性定義のために1行、ログのために1行)。つまり、何のコンフィギュレーションも行わなければ最も適切なデフォルト設定が適用されるということだ。 これにより「とりあえずログを取りたい」というライトな需要も、「がっつりカスタマイズしたい」というヘヴィーな需要も満たせるようになっている。
// build.sbt libraryDependencies += "com.outr" %% "scribe" % "3.13.1" // foo.scala scribe.info("Yes, it's that simple!")
柔軟性と高い直交性
Scribeはそれを利用するScalaコードベースのセマンティクスに一切介入することなく(つまりヘンなことはしない)、独立性の高いライブラリとしてロギングを行う。Scribeはいくつかの分かりやすい部品に分かれており、これらを入れ替えることで動作をカスタマイズできる。そしてこれらの部品は標準的なScalaのコードとして提供される。
したがって、普通にScalaを書くようにロガーの動作を書き換えることができる。よくわからない設定ファイルを書く必要はまったくない。全ての設定はコードである。
// ロギングフォーマットを変更している
Logger.root
.clearHandlers()
.withHandler(formatter = scribe.format.Formatter.advanced)
.replace()
ハイパフォーマンス
リフレクションなどの要素を使わずに、必要な情報をなるべくコンパイル時に得る設計により、Scribeは並外れて良好なパフォーマンスを誇っている(log4jの3倍程度)。行数などの情報を盛り込むとさらに差が開く。
Scribeの基礎
この節では、Scribeの基本的な使い方について説明する。といっても簡単なのであまり説明できることはないのだが・・・
まずはScribeを依存性に追加する(バージョンは執筆時点での最新)。
libraryDependencies += "com.outr" %% "scribe" % "3.13.1"
文字列をログする
文字列をログするには、scribe.infoを呼ぶ。ログレベルに応じて、warnやdebug、errorなどもある:
scribe.debug("Reading API") scribe.warn("API exceeding soft timeout!") scribe.error("File not found!")
データをログする
scribe.data()を利用すると、文字列に限らず、汎用的なデータをログに含めることができる:
import scribe.data val magicNumber = 42 scribe.error("invalid number", data("number", magicNumber))
キーと値を渡すほかにも、直接Mapを渡す方法もある。
例外をログする
ScribeはThrowableを直接ログできる。catchしたときに使うと便利だろう。
scribe.error(new Exception("Exception from Scribe."))
2024.03.21 23:24:02:361 sbt-bg-threads-3 ERROR <empty>.Main.hello:18
java.lang.Exception: Exception from Scribe.
at Main$package$.hello$$anonfun$6(Main.scala:18)
at scribe.LogFeature$.throwable2LoggableMessage(LogFeature.scala:18)
at Main$package$.hello(Main.scala:18)
at hello.main(Main.scala:7)
ログフォーマットを変更する
以下のようにしてルートロガーのHandlerの中のformatterを差し替えるとよい。
いくつかのデフォルトフォーマットがscribe.format.Formatterに提供されているので見るとよい。
Logger.root
.clearHandlers()
.withHandler(formatter = scribe.format.Formatter.advanced)
.replace()
これだけでかなりのユースケースをカバーできるだろう。
Scribeの発展的利用
この節では、Scribeをカスタマイズしたり細かい箇所に手を入れるための知見を紹介する。
ざっくり分かるScribeのしくみ
Scribeは、プログラマブルなロギングライブラリである。つまり、ソフトウェアの動作時に直接ロガーの動作を書き換えることが可能だ。
この節では、Scribeを構成するLogRecordやLoggerといった概念について簡単に説明する。
LogRecord
Scribeでロギングを行う際、最も基本的な単位になるのがLogRecordだ。これは「ログされるべき1つの記録」であり、われわれがログするときの単位でもある。エンドユーザはこれを直接生成することはないが、カスタマイズする際に時おり登場する。
LogRecordは他にあるScribeのコンポーネントの中を旅してまわり、最終的に画面やファイルに出力されその一生を終える。
Logger
「ログさせてくれ!」とエンドユーザが唱えるとき、まず応対するのがLoggerだ。直接Loggerがwarnなどのメソッドを提供するわけではないが、ログの流れの主体となる最も大きな存在がLoggerである。
Loggerは階層構造にすることができ、子が受け取ったLogRecordは親階層のLoggerもこれを受信する仕組みになっている。DOMのイベントバブリングの仕組みに近いと言ったら分かってもらえるだろうか。この仕組みは出力などの柔軟性のために用意されているが、最初のうちはあまり使わないだろう。Scribeはデフォルトでscribe.Logger.rootを提供しており、何も指定しないとこのLoggerが呼び出される。
ちなみに局所的にLoggerを作りたい場合はscribe.Logger("名前")とすればその場で作成される。rootロガーに伝播させたくない場合はscribe.Logger("名前").orphan()とすることで親設定を捨てることができる。
modifiers
Loggerにはmodifiers: List[LogModifier]というフィールドがある。Loggerは受け取ったLogRecordを順にLogModifierに適用してから出力しようとする。
LogModifierは実質的にLogRecord => Option[LogRecord]のようなシグネチャになっている。つまりログしないことを選択できるようになっている(このユースケース専用に、FilterというLogModifierの一種も用意されている)。要するに、modifierは標準ライブラリで言うところのcollectで、Filterはfilterだと考えてよい。
handlers
Loggerにはhandlers: List[LogHandler]というフィールドがある。これは、LogRecordを受け取って何らかの副作用(典型的には、画面に表示するとか通知するとか)を惹起するものとして定義されている。これもmodifiersと同じく、Loggerは受け取ったLogRecord(を加工したもの)を順にLogHandlerに適用していく。
LogHandlerはいくつかの部品で構成されており、それらが揃ってはじめてLogHandlerとなる。
formatter: FormatterLogRecordをLogOutputに変換する部品。- デフォルトのフォーマッタがあらかじめ用意されている。
- ここをいじると出力の仕様を変更できる。
writer: Writer- 実際にファイルに出力したり画面に出力する責務を担う部品。
- たとえばモジュール
scribe.fileはファイルへの書き込みを行うFileWriterを提供する。 - たとえばモジュール
scribe.jsonは既存のWriterをラップする形で、LogRecordをJSONに変換して出力する。
minimumLevel: Level- Handlerが処理すべき最小限のログレベルを指定できる。
- これにより、重大なログのみSlackに通知する、といった挙動が可能になる。
modifiers- Handler内で局所的に利用される
LogModifierを与えることができる。
- Handler内で局所的に利用される
重要な挙動として、以下の点を覚えておくと便利だ:
- Loggerは
withModifierやwithHandlerでLogModifierやLogHandlerを積み増しできる。 - Loggerは
clearModifiersやclearHandlersでLogModifierやLogHandlerを全部消すことができる。

LogOutput
実際に出力されるのを待っている状態のログを表現したものがLogOutputだ。これは内部的には構文木の状態になっている。直接Stringにしないのは、例えばWriterが色コードを読み飛ばして白黒のまま出力したりできるようにするため。
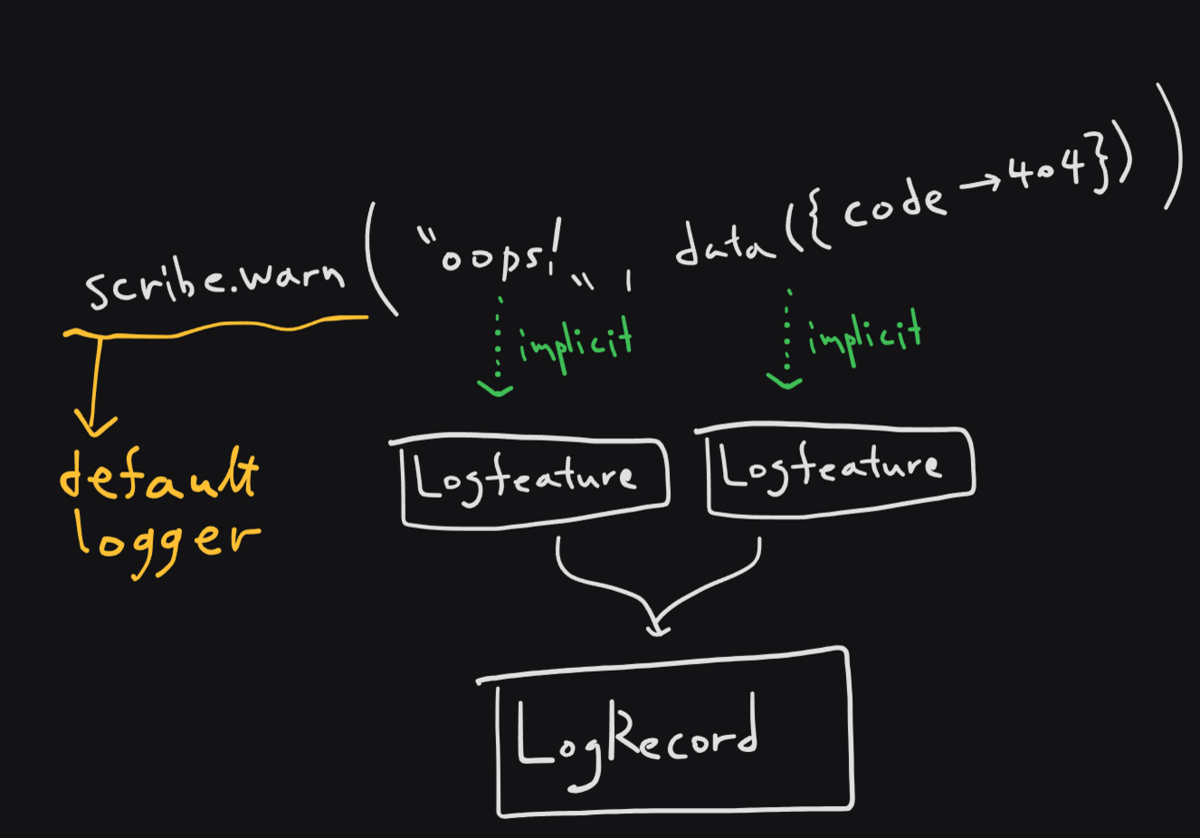
LogFeature
「何をログできるのか」を定義するものがLogFeatureだ。典型的には文字列に対するLogFeatureが用意されている。また、基礎コーナーで紹介したdata()もLogFeatureが用意されたオブジェクトだ。
LogFeatureの実質的な中身はLogRecord => LogRecordになっている。最初は空のLogRecordに徐々に値を積み込んでいくイメージだ。例えば文字列をロガーに渡すと、string2LoggableMessageによって文字列がLogFeatureに変換され、出力結果として使われるようになる。
この仕組みはLogModifierに似ているが、LogModifierはロガーに従属するのに対してLogFeatureはログする時にユーザ側が渡すという意味合いの違いがある。より呼び出し側に近い概念だ。この柔軟性によって、ほぼあらゆるものをロギングできるようになっている。
Q&A
JSONを出力したい(構造化ロギングをしたい)
JSON出力用のモジュールを依存性に入れて、writerを書き換えるとよい。
libraryDependencies += "com.outr" %% "scribe-json-circe" % "3.13.2"
import scribe.writer.ConsoleWriter scribe .Logger .root .clearHandlers() .withHandler( writer = scribe.json.ScribeCirceJsonSupport.writer(ConsoleWriter) ) .replace() // replaceすると既存のLoggerを置換する scribe.info("Logging in JSON format.")
{ "messages": [ "Logging in JSON format." ], "service": null, "level": "INFO", "value": 300, "fileName": "Main.scala", "className": "<empty>.Main", "methodName": "logInJson", "line": 49, "thread": "sbt-bg-threads-1", "@timestamp": "2024-03-28T12:19:14.221Z", "stack_trace": null, "mdc": {}, "data": {} }
JSONに追加のフィールドを入れたい
残念ながらその機能は…………と言おうとしていたが、Issueを立てたところその機能が生えた。
ScribeCirceJsonSupportを継承してjsonExtrasメソッドを実装すればよい。デフォルトでは渡ってきたJSONをそのまま返すような実装になっているので、フィールドを追加したJSONを返してやるようにすればいい。あとはこうして作ったobjectをScribeCirceJsonSupport.writerのかわりに使うだけでよい。
object MyJsonSupport extends scribe.json.ScribeCirceJsonSupport { import io.circe._ override def jsonExtras(record: LogRecord, json: Json): Json = { json.deepMerge( Json.obj( "hello" -> Json.fromString("world") ) ) } } scribe.Logger .root .clearHandlers() .withHandler(writer = MyJsonSupport.writer(ConsoleWriter)) .replace()
メッセージとは別に追加のデータを出力したい
data()というLogFeatureを使いましょう。
import scribe.data val temp = 42 scribe.warn("it's very hot!", data("temperature", temp)) // LogFeatureはいくつでも入れられる scribe.info("foo", "bar", "buzz")
時刻形式を変更したい(もっとフォーマットをいじりたい)
LogHandlerのFormatをいじるとよい。既存のフォーマッタをコピペしてきて時刻部分だけいじる。さいわいにもISO8601は最初から用意されている。
val mySuperDuperFormatter = { import scribe.format._ import scribe.format.Formatter._ fromBlocks( FormatBlock.Date.ISO8601, space, openBracket, threadNameAbbreviated, closeBracket, space, openBracket, levelColoredPaddedRight, closeBracket, space, green(position), string(" - "), messages, mdc ) } scribe.Logger.root.clearHandlers().withHandler(formatter = mySuperDuperFormatter)
記録するログレベルをいじりたい
LogHandlerのminimumLevelをいじるとよい。
Logger.root
.clearHandlers()
.withHandler(
minimumLevel = Some(scribe.Level.Info), // Info以上しか記録されない
)
.replace()
ログの一部を強調したい
import scribe.output._を使ってout(red("Danger!!"))を渡すなどすると部分的に強調できる。
import scribe.output._ // outは複数のLogOutputを1つにひっつける君 scribe.error(out("this is ", red(bold("very dangerous")), "!!!"))
特定の型にセンシティブなデータが含まれているので隠蔽したい
これはあまりScribe関係ないけど、case classで隠蔽してtoString()を書き換えるのがよいのではないかと思います。
case class Password(value: String) { override def toString(): String = "<confidential>" } case class User(name: String, password: Password) scribe.info( "Logging a user", data("user", User("John", Password("secretpassword1234"))) ) // => Logging a user (user: User(John,<confidential>))
Opaque Typesが使えるかと思ったけど、Opaque Typesに対するextension methodでは既存のメソッドのオーバーライドはできないようだ。
一定範囲のコンテキストで値を保持したい
これはMDCという機能を使うとできます。がここでは割愛。
MDC { implicit mdc =>
scribe.elapsed {
Thread.sleep(1000)
scribe.info("Elapsed time measured.")
}
}
こんな感じの面白い機能もあります。これはelapsedの中に突入してからどのくらい経過したかを同時にログしてくれる機能。
所感
日本語記事がぜんぜん無いのでまあソースコードを読んで自分がファーストペンギンになるしかないわけです。これだけ書いたらちょっとは使ってもらえるでしょう。
これだけ書いてきて思いましたが、Scribeは作りが素直なせいで普通に書き換えてカスタマイズできます。ヘンな魔術的な仕組みを使っているところがあまり無いんですね。コードを辿ったらScalaのコードが書いてあって、ちょっと差し替えたり継承したりしたらちゃんと動く、みたいな感じです。設定ファイルという概念を捨てているからこそできるシンプルさかもしれません。それでいてかなり柔軟で良い子です。
「これどうやるの?」みたいな所があったらはてブか何かにコメントください。ここに追記していこうと思います。