Scalaの非同期・ストリーミング処理ライブラリであるfs2で、ジョブキュー的な感じで、複数のワーカにデータを分散して配りたいことがあり、それの実現方法について調査したメモ。
追記(2023-09-23)
fs2 3.9.2で確認したが、stream.parEvalMap(N)(IO)の形でparEvalMapを呼ぶことで並列実行が可能だ。
tl;dr
1つのQueueにデータを入れて、複数のワーカから好きに取出せばよい。
Streamを複数のPipeに分散させるには?
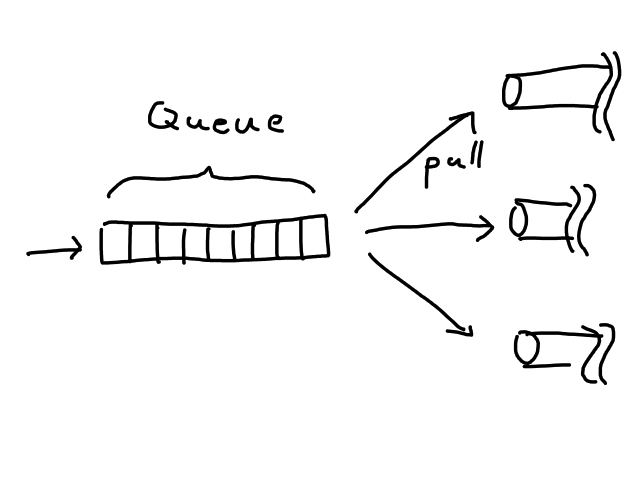
FS2の以前のバージョンにはBalanceという要素が用意されていたのだが、機能の統廃合によって消えてしまった。Discordで様子を見るとQueueとWorkerで作れるとのことなので、作ったところ、作れた。
この構成では、パイプラインは3つの要素に分解される。
- これから分散して処理しようとするデータを送出する
Stream QueueStreamのデータ送出速度と、複数のワーカの処理速度との差異を吸収する- 同じデータが別のワーカに同時にpullされることを防ぐ
- 実際にデータを処理する
Pipe
Queueへの投入や取出しは副作用をともなう操作である。したがってStreamが副作用処理用に用意したメソッドを経由してデータの受け渡しを行う。
また、この実装では厳密に元々のBalanceに基いているかは確認していない。今回実装するバージョンはワーカが暇になり次第Queueからデータを取りに行くが、元々のバージョンではそれなりに負荷を分散させていたかもしれないのでそこだけ注意してほしい。
基礎の復習
- Stream: データが流れ出てくる蛇口
- Pipe: データを受け取ってデータを流れ出す土管
- Fiber: 軽量スレッド(ThreadをモジってFiber??)。Cats Effectがランタイムとして動かしてくれる
io.start: IOを他のfiberに放り投げて非同期化するときに呼ぶメソッド。他言語でいうspawnみたいな雰囲気?
Stream
データを送出するStreamは別に何でもよい。ここでは時刻を100ミリ秒ごとに送出することにする。
def streamBySecond: Stream[IO, String] = Stream.awakeEvery[IO](FiniteDuration(100, "millisecond")).map(_.toString)
ジョブキューだとここはジョブの情報になるだろうし、ActivityPubを実装してるのであればあなたの投稿が流れてくるかもしれない。
Queue
cats.effect.std.Queueがキューの実装を提供してくれているので、これを使うだけでキューは完成する。キューは状態を持つ副作用要素なのでIOにくるまれて提供される。Queueに対する操作はアトミックであり、同時にアクセスしてもよしなに処理される。
個数制限付きのBounded Queueと、個数制限がないUnbounded Queue、個数が0個で実質的に同期的に振る舞うSync Queueなどを使えるが、いったんここは長さ10のBounded Queueにした。ちなみにキューが満杯のときに詰め込もうとするとファイバーがブロックする仕組みになっている。
for { q <- cats.effect.std.Queue.bounded[IO, String](10) // qの型はQueue[IO, String] } yield ???
ちなみにキューに何かを入れるにはq.offer("foo")とする。これも副作用なのでIO[Unit]となる。
Pipe
実際にデータを処理するPipeとして、画面に処理内容を表示するだけの単純なものを想定する。実際は時間がかかったり様々な副作用が発生することが予期される。
def worker(id: String): Pipe[IO, String, Unit] = _.evalMap { s => IO.println(s"worker $id: processing $s") }
あとはこのPipeにQueueから取出したデータを流し込めばよい。
QueueをStreamに繋ぐ方法はシンプルである。StreamとQueueとの組み合わせはポピュラーなので、fs2が提供している便利なメソッドを呼べばよいのだ。
Stream.fromQueueUnterminatedを使うと、指定したキューから順にデータを取出して流すようなStreamが得られる。
def workerStream(id: String, q: Queue[IO, String]): Stream[IO, Unit] = Stream .fromQueueUnterminated[IO, String](q, 1) .through(worker(id))
連接
最後に、これらの構成要素を接続することでQueueを使ったデータ処理パイプラインが完成するが、その前に、ワーカの数を1つに絞った構成を用意することで、全体の構成を把握する。
val run: IO[Unit] = for { // キューを作成する q <- Queue.bounded[IO, String](10) // キューにデータを投入していくStreamを作り、.compile.drainを呼んで起動する。 // 起動したStreamは停止するまで処理を返さないので、.startで別Fiberに移す。 _ <- streamBySecond.evalMap(s => q.offer(s)).compile.drain.start worker <- workerStream(s"worker 1", q).compile.drain } yield workers
このプログラムを起動すると、以下のように表示される:
worker worker 1: processing 518027376 nanoseconds worker worker 1: processing 1002066954 nanoseconds worker worker 1: processing 1503024474 nanoseconds worker worker 1: processing 2002512613 nanoseconds worker worker 1: processing 2503142667 nanoseconds worker worker 1: processing 3002622913 nanoseconds worker worker 1: processing 3502740043 nanoseconds ...
正しくQueueにデータを追加でき、Queueからデータを取り出すことができた。しかしこれでは単にStreamにPipeを繋いだほうがよい。Queueを介するメリットは、複数のワーカがQueueから好き勝手にデータを引っぱってきても安全に処理できることである。これを示すために、ワーカを50個作成してみよう。
val run: IO[Unit] = for { q <- Queue.bounded[IO, String](10) _ <- streamBySecond.evalMap(s => q.offer(s)).compile.drain.start // workerStreamを50個作成し、parSequenceで同時に起動する workers <- (1 to 50) .map(id => workerStream(s"worker $id", q).compile.drain) .toList .parSequence } yield workers // ここでWorkersの型はSeq[Unit]になっている
このプログラムを起動してみよう:
worker worker 4: processing 114963292 nanoseconds worker worker 12: processing 202711223 nanoseconds worker worker 3: processing 301874858 nanoseconds worker worker 2: processing 402285444 nanoseconds worker worker 6: processing 503049804 nanoseconds worker worker 8: processing 602845003 nanoseconds worker worker 7: processing 703135058 nanoseconds worker worker 9: processing 802909541 nanoseconds worker worker 11: processing 902173113 nanoseconds worker worker 10: processing 1001909210 nanoseconds worker worker 5: processing 1102346783 nanoseconds worker worker 1: processing 1202852437 nanoseconds worker worker 13: processing 1303149172 nanoseconds worker worker 14: processing 1402490756 nanoseconds worker worker 15: processing 1502714526 nanoseconds worker worker 17: processing 1602479306 nanoseconds worker worker 16: processing 1702322602 nanoseconds worker worker 18: processing 1802995540 nanoseconds worker worker 19: processing 1902201093 nanoseconds worker worker 20: processing 2001744269 nanoseconds worker worker 21: processing 2102105174 nanoseconds worker worker 22: processing 2201823844 nanoseconds worker worker 23: processing 2302470145 nanoseconds
ワーカが同時に実行され、ばらばらなワーカにデータが送り付けられていることがわかる。というより、ワーカがQueueから好きなタイミングでデータを取り出しているというイメージが近い。Queueはスレッドセーフなので、必ず投入した順序にデータを返すし、別のワーカに同じデータを返すことはない。
全コード
//> using scala "3.2" //> using lib "org.typelevel::cats-effect:3.4.8" //> using lib "co.fs2::fs2-core:3.6.1" import cats.effect.IO import cats.effect.IOApp import cats.effect.std.Queue import cats.implicits._ import fs2.Pipe import fs2.Stream import scala.concurrent.duration.FiniteDuration object Main extends IOApp.Simple { def worker(id: String): Pipe[IO, String, Unit] = _.evalMap { s => IO.println(s"worker $id: processing $s") } def workerStream(id: String, q: Queue[IO, String]): Stream[IO, Unit] = Stream .fromQueueUnterminated[IO, String](q, 1) .through(worker(id)) def streamBySecond: Stream[IO, String] = Stream.awakeEvery[IO](FiniteDuration(100, "millisecond")).map(_.toString) val run: IO[Unit] = for { q <- Queue.bounded[IO, String](10) _ <- streamBySecond.evalMap(s => q.offer(s)).compile.drain.start workers <- (1 to 50) .map(id => workerStream(s"worker $id", q).compile.drain) .toList .parSequence } yield workers }
Further step
スロットリングを行いたい場合は、以下のようなライブラリを使い、適切な箇所に挟むだけで実現できる。速度制御が必要なアプリケーションを実装する際に役立ててほしい。
↑これはトークンバケットアルゴリズムによる速度制御。
↑こちらは速度に加えて「同時にいくつまで」といったより細やかな制御が可能。
まとめ
- Cats Effect 3が提供する
Queueとfs2が提供するStreamとを組み合わせることで、バッファリングされたジョブキューを構成できることを示した。 Queueのアトミック性により、Streamを増やして並行実行しても問題を起こさないことがわかった。Queueを介すると間接的なStream間のデータ転送に応用できることを示した。
参考文献
元ネタの記事はこちら。