特定のリズムにあてはまる日本語を頑張って探したくなることがたまにある。そして、定期的に↑のような記事が流行っては、仕事が手につかなくなる!このままでは、○ー○ー○○ー○ー○ーを考える時間によって日本のGDPが押し下げられてしまう。
そこで機械の力を借りて特定のリズムを持った言葉を探せるようにした。
自分のマシンだと、だいたい2分で目当ての言葉を探してくれるようになった。
使い方
基本的にリポジトリに書いてあるけれど、やることは2つ。Scalaなのでsbtが必要。
- Wikipediaのデータを落としてきて解凍する
sbt "run .-.-..-.-.-"のように「○」を.に置換し、「ー」を-に置換した文字列を渡して起動する
2分ほど待てば結果が返ってくる。
仕組み
構成は、Scala + Akka Streamsによるストリーム処理をやっている。Akka Streamsはストリーミング処理のためのライブラリで、簡単にストリーミングパイプラインを作成したり、それをTCPで流したり、ファイルに保存したりと、かなり自由で実用的な処理を行うことができる。
素材選び
ありとあらゆる言葉から探してくる必要があるので、Wikipediaのデータをダンプしたものを素材として用いることにした。これくらいあれば同じリズムの言葉くらい見付かるであろう。
記事全体を使う必要はなくて、タイトルと最小の段落だけが収められた2.2GB(!)のデータを入手できるのでこれを使う。(なんかビッグデータ時代だと2GBって言ってもまあそんなもんか、って気持ちになるよね。)
Wikipediaの記事には大抵カッコ書きで読み仮名も書いてあるので、特別な解析なしにそのまま使うことができる。
リズム形式
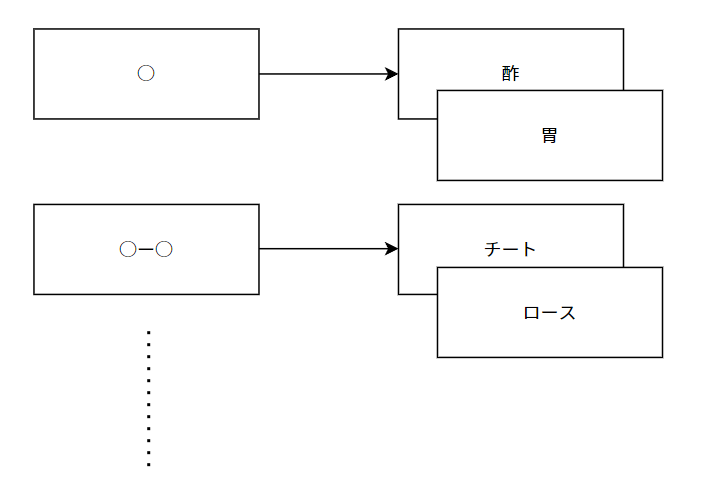
同じリズムの言葉を探す上で、今回素材から取り出したいのは「○ー○ー○○ー○ー○ー」のようなリズムを表現した形式である。とりあえずこれをリズム形式と呼ぶことにする。
可能な限り全ての記事のリズム形式を作成し、リズム形式をキーとした辞書に格納していけば、特定のリズムを持った言葉の集合が手に入る。
Scalaで実装するので、これはmutable.Map[String, Seq[String]] で実装する。value部がmutableでないのは、そんなにコストがかからないだろうと思って省略したためである。
ちなみに、辞書を使わずに「○」と「ー」のノードで構成されたトライ木もどきを実装するというアイデアもあったが、先頭マッチといった使い道はないことから実装するメリットがないと判断して使わなかった。今回は、パターンに対応するタイトルの集合が得られれば良いのだ。
実装
データを全部メモリに載せると重そうなのでストリーミング処理しながらリズムを解析していくことにした。ストリーム処理はいくつかの段に分けた。
- 素材はXMLドキュメントとして提供されるので、これをパースして
<abstract>要素だけ取り出す段。 - abstractのうち、読み仮名の箇所だけを取り出す段。
- 読み仮名をリズム形式に変換する段。
- リズム形式をキーとして、辞書にタイトルを格納していく段。
- 最終的に探したいリズム形式に対応するタイトルを表示する段。
XMLの処理が一見面倒そうだが、Akka Streams用の追加モジュール群であるAlpakkaがXML用モジュールを提供してくれているので、おんぶにだっこで簡単に実装が終わった。
さて、各段に対応する箇所は以下の通り。
val foreach: Future[IOResult] = FileIO .fromPath(file) .map(ByteString(_)) .via(XmlParsing.parser) .statefulMapConcat(() => { // 1. // state val textBuffer = StringBuilder.newBuilder // aggregation function parseEvent => parseEvent match { case s: StartElement => textBuffer.clear() Seq.empty case s: EndElement if s.localName == "abstract" => val text = textBuffer.toString Seq(text) case t: TextEvent => textBuffer.append(t.text) Seq.empty case _ => Seq.empty } }) .map(extractName) // 2. .map { case Some((Some(name), Some(punct))) => val ddpunct = DotDashMap.dotDashParse(punct) // 3. // println(s"$ddpunct => $name") if (ddpunct == pattern) { println(s"$name") } ddMap(ddpunct) = ddMap(ddpunct) :+ name // 4. case otherwise => () } .to(Sink.ignore) .run() Await.result(foreach, Duration.Inf) println(ddMap.get(pattern)) // 5.
追加処理として、拗音を正規化したり、カタカナをひらがなに直したり、中黒を取り去ったりといった地味な処理もしているが、これはdotDashParseあたりでがんばってやっている。日本語処理はつらい。
2.2GBあるデータをぐんぐん飲み込んで書いた通りにちゃんと処理できたので、Akka Streams頑健だなぁと思った。思ってたよりも速いし。
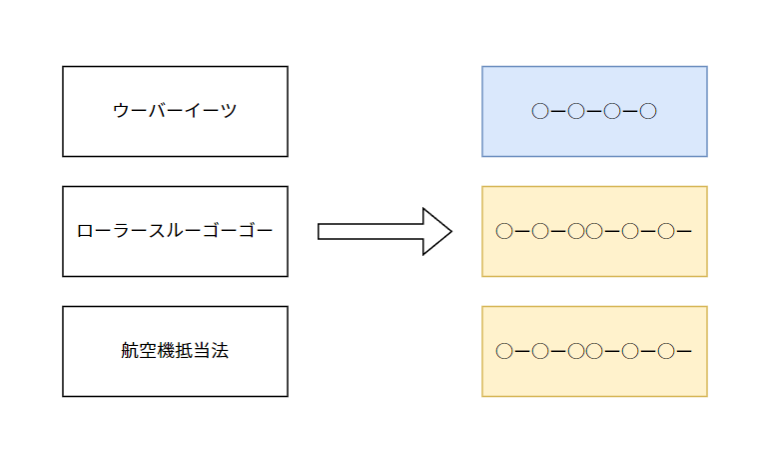
で、○ー○ー○○ー○ー○ーはなんなの
windymelt% sbt "run .-.-..-.-.-" [info] welcome to sbt 1.6.2 (Ubuntu Java 11.0.14.1) ... [info] running windymelt.Hello .-.-..-.-.- 航空機抵当法 ローラースルーGOGO 西洋の命数法 包頭軌道交通 西寧軌道交通 「No Need 2 Worry」 総合治療効用 Some(List(航空機抵当法, ローラースルーGOGO, 西洋の命数法, 包頭軌道交通, 西寧軌道交通, 「No Need 2 Worry」, 総合治療効用)) [success] Total time: 119 s (01:59), completed 2022/04/17 19:34:09
航空機抵当法
航空機抵当法(こうくうきていとうほう、昭和28年7月20日法律第66号)は、航空機に関する動産信用の増進により、航空の発達を図ることを目的(第1条)とする日本の法律。
意外なことに日本の法律がヒットして面白い。かなり昔からある法律だった。
ローラースルーGOGO
ローラースルーGOGO(ローラースルーゴーゴー)とは1974年(昭和49年)に日本で発売された乗用玩具。
冒頭の記事でも紹介されていたやつ。謎玩具。

西洋の命数法
西洋の命数法(せいようのめいすうほう)では西洋の諸言語における命数法について述べる。
名前じゃないけど解説記事になってるシリーズ。こういう記事あるんだ。
包頭軌道交通
包頭軌道交通(ほうとうきどうこうつう、中文表記: 包头轨道交通)は、中華人民共和国内モンゴル自治区包頭市において開業予定の地下鉄である。
モンゴル自治区の地下鉄が登場。日本語じゃない。
西寧軌道交通
西寧軌道交通(せいねいきどうこうつう、中国語: 西宁轨道交通)とは中国青海省西寧市において計画中の地下鉄である。遠期計画では地下鉄3路線と郊外鉄道4路線が計画されている。近期計画では1号線と3号線一期区間、計47.7kmが建設され、建設費は280.61億元の予定である。1号線は2016年内に着工され、現在予定が未定となっている[1]。
まさかの中国の地下鉄二連発。どっちも開通していないのが面白い。
No Need 2 Worry
「No Need 2 Worry」(ノー・ニード・トゥー・ウォーリー)は、YOKO Black. Stoneの2枚目のシングル。1998年4月1日にStyling RecordsからCDとしてリリースされた。
音楽がヒットした。音楽は件数も多そう。
総合治療効用
総合治療効用(そうごうちりょうこうよう、Overall treatment utility;OTU)は、悪性腫瘍の治療効果や副作用に加え、緩和治療の効果やQOL、患者の忍容性や満足度を総合的に評価する指標である[1]。
医学ジャンルでもヒットした。
結語
困ったときはいつでも調べられるようになったので、同僚が韻を踏めずに困っているときに助けてあげたい。
辞書は一度構築したら使い回すことができるので、ファイルにMessagePackとかでキャッシュするメカニズムも実装すればすぐ作れそう。とはいえ2分くらいなら毎回待ってもいいかな、と思っている。