百聞は一見に如かず:
import pandas as pd df = pd.DataFrame( [["foo", "apple", 12], ["bar", "banana", 30], ["buzz", "apple,banana", 15], ["qux", "chocolate,banana", 51]], columns=['id','like', 'age'] ) df
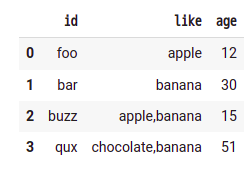
こういうDataFrameがあったとする。likeカラムは,でseparateされていて、このままだと使いにくい。実際、こういうパターンはGoogle Formの入力結果をパースするときに出現する。複数選択可能なオプションはこういう形で出力されるのだ。
この状態から、次のような状態に持っていきたい:
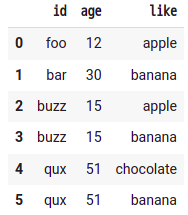
ここまで展開するためには、数段階を踏む必要があるので、解説する。やることは以下の通りだ:
likeカラムを分解し、idカラムをインデックスとするDataFrameを生成する- 前述のDataFrameと、元々あったDataFrameをmergeする
さあはじめよう。
split と stackのコンボ技を決める
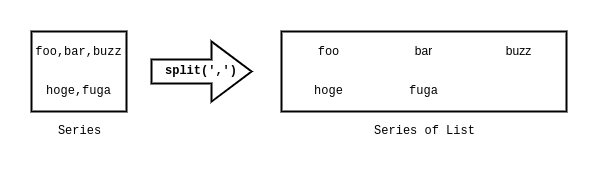
カンマなどのdelimiterで分割されたカラム、より正確にはSeriesを分解するには、まずsplit()を使う。これにより、Seriesは各部分を格納したListのSeriesに分解される。
ただ、Seriesが横に増えても使いにくいだけなので、さらにstack()を用いてカラムを「縦」に展開する。
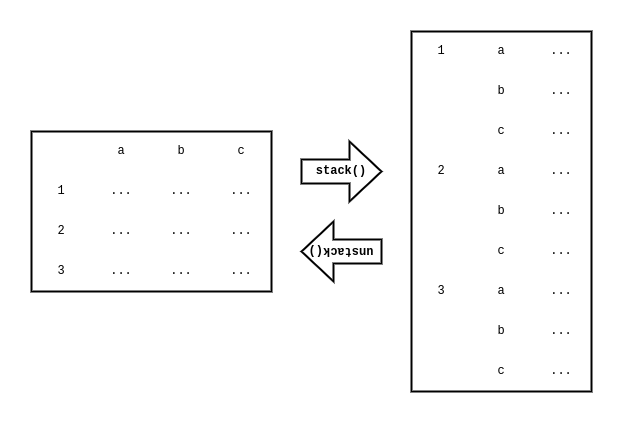
ただし、stack() はDataFrameに対して定義されており、Seriesに対して使うことができない。このため、一度SeriesをDataframeに変換する処理を挟む。
splitted_series = df.like.str.split(',')
splitted_df = pd.DataFrame(splitted_series.to_list(), index=df.id).stack()
ここまでを表現したのが上掲のコードである。
ここで注意しておきたいのが、split()に付帯するexpandオプションを使わないことだ。expand=Trueを指定することにより、自動的にDataFrameを返すこともできるのだが、後でマージすることを考えて、手動でindexを与えたかったので、今回は使わずに手でpd.DataFrameを呼び出している。
インデックスの微調整
どうやら、stack()したデータにはMultiIndexという特殊なインデックスがつくみたいだ。
splitted_df.index
MultiIndex([( 'foo', 0),
( 'bar', 0),
('buzz', 0),
('buzz', 1),
( 'qux', 0),
( 'qux', 1)],
names=['id', None])
MultiIndexは、データベース風に言うと複合キーみたいなもので、いくつかの値をタプルで組合わせて1つのキーとして振る舞うようにしている。ちなみにMultiIndexのいくつめの値かをlevelといい、最も外側が0、内側に行くほど数字が増えていく。
ここではMultiIndexの2つめの値(つまりlevel=1)として、stack()したときの順序が入っているらしいことがわかる。
今回はこの数字は不要なので、reset_index()を用いてMultiIndexのlevel 1の値を消去する。
splitted_df = splitted_df.reset_index(1)
カラム名の微調整
この時点でsplitted_dfは以下のような状態になっている:
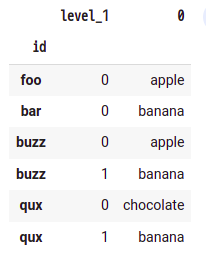
MultiIndexから押し出されたカラムが増えているのがわかる。
各カラムに名前をつけて、不要なカラムを消してしまおう:
splitted_df.columns = ['subidx', 'like'] splitted_df = splitted_df[['like']]

元DataFrameとの結合
splitted_dfは綺麗になったが、最初に定義したDataFrameに含まれていたageカラムは含まれていない。最終的なデータを完成させるために、idカラムをキーとしてdfとsplitted_dfとを結合しよう。
DataFrameを結合するには、pandas.mergeを使う:
pd.merge(df[['id', 'age']], splitted_df, on='id')
デフォルトでうまく結合キーを見付けられることもあれば、見付けられないこともあるので、on=で結合キーを明示的に与えるほうが安心だし、メンテナビリティも高いからおすすめだ。
細かい注意点として、元々のdf.likeカラムは不要になったから意図的にdf[['id', 'age']]として排除していることに留意しよう。
この結果、以下のようなDataFrameが得られる:
やったね。
つまづいたところ
- MultiIndexについて知っていないと、
stack()した後で不可解な挙動に悩まされることになる。うまくmergeできないときは、.indexでindexがどうなっているか確認しよう。stack()は自動的にMultiIndexのlevelを増やすという性質がある。indexの一意性を保つためにおそらく必要な挙動なのだろう。
merge()がうまくキーを見付けられないことがあった。right側のDataFrameはあらかじめ結合キーをDataFrameのindexにしておくとスムーズな気がする。
参考文献
Have a nice Pandas life!