趣味のプログラミングなどに使っている自作PCのメモリが最近キツくなってきており、ブラウザを開きつつStable Diffusionなどを回していると16GBでは結構辛いものがある。Scalaのコンパイルなどでも結構なメモリが消費される。
そこでメモリを買って16GiBから32GiBにまで増やすことにしたのだが、メモリクロックをどうするか考えることになった。
TL;DR
ぜんぜん影響ないので標準クロックのやつでいいです。相性や起動しないリスクを取ってメモリOCをするのはやめておきなさい
メモリクロック
読者諸君はメモリクロックを知っているだろうか。メモリの型番の後に2666とか3200とか書いてあるのがそれだ。基本的にメモリクロックはJEDECという機関が標準化しており、何も設定をしない状態では規格値でメモリは動作するように設計されている。 しかし、メーカは良品を選別して規格よりも高速に動作するメモリチップを組み合わせた高規格品を独自に製造している。例えばDDR4の規格上の上限は2666MHzであり、それ以上の動作クロックで売られているメモリは高規格品だ。規格上では2666MHzで動けば良いのだが、この製品はもっとオーバークロックできますよ、というのを保証して売っているのだ。例えば今回購入したコルセアのメモリは3200MHzでの動作をサポートしている。
メモリオーバークロックはCPUのオーバークロックと同じく、正式に保証された動作ではないため、CPUやマザボとの相性によって動作しない場合があることに注意だ。しかしチューニングとしては一般的で、マザーボードの設定画面に入ると比較的簡単にクロック数を調整できる。これはXMPといってメモリオーバークロックのための規格があらかじめ設定されており、「このくらいならいけますよ」とメモリが自己申告するようなメカニズムがあらかじめ存在するため、ユーザはクロック選択肢を選ぶだけでオーバークロックが可能なのだ。もちろん相性で起動しなくなるおそれもあるので自己責任だ。
ちなみに、高規格のメモリであっても低い規格で動作させることは可能だし、クロックの規格が混在したメモリをマザーボードに載せた場合は勝手に低いほうの規格で動作するようになる。もちろん相性が合えばの話だが。
プログラミングとメモリクロック
メモリオーバークロックをするとして、どのくらい効くのだろうか。調べてみると、やれゲームのFPSだとか、動画編集ツールの速度といった指標が出るばかりで、コンパイラやopensslのスループットについての情報はほぼ存在しない。自分は自作マシンでは主にプログラミングをやるので、プログラミングでどうなるかが知りたいのだ。一般的にはメモリオーバークロックを行っても大してゲームのFPSには影響しないことが知られているが、ひょっとしたらコンパイラは高速になるかもしれない。そう思った自分は、3200MHzのメモリを人柱として購入し、プログラミングまわりのタスクのスループットがどのように変化するか調べることにした。
![CORSAIR DDR4-3200MHz デスクトップPC用 メモリ VENGEANCE LPX シリーズ 32GB [16GB×2枚] CMK32GX4M2E3200C16](https://m.media-amazon.com/images/I/41W8FzNy-zL._SL500_.jpg "CORSAIR DDR4-3200MHz デスクトップPC用 メモリ VENGEANCE LPX シリーズ 32GB [16GB×2枚] CMK32GX4M2E3200C16")
購入したのはこれ。
調査
以下のような方法で検証を行った。
- 仮説: プログラミング、特にコンパイルはCPUバウンドな処理を行うため、メモリクロックはコンパイル時間に影響を及ぼすのではないか
- 実験:
- 現在2666MHzで駆動している自作マシンのメモリのクロックを1333MHzにまで下げ、いくつかの作業を行わせる
- 同じことを2666MHzに戻して再度行い、時間を測定する
- 3200MHzで動作するメモリが届いたらこれに差し替え、様子を見る
- 容量の影響があるかもしれないので
htopしながらメモリ使用量を監視しつつ実験する- 結論から言うと16GiB以上のメモリは消費しなかったので、メモリ量の影響は無かったと考えている(厳密にやるなら新メモリで実験をやりなおすことになりそう)
- 作業:
- 動画変換: x264でGPUを使ったエンコードを行わせる。おそらくGPUバウンドなので影響はないのではないか
- コンパイル: CとScala(JVM)で大きめのプロジェクトをコンパイルさせ、その実行時間を計測する
- CPUバウンドだが、細かくファイルを読み書きすることが予想されるので影響するか不明
- 暗号化: 3GiB程度の大きなランダムなファイルを
opensslを用いて暗号化する- 完全にCPUバウンドな処理になるが、読み書きに律速されるのではないか
- コンパイルとは異なり、シングルスレッドで動作する
- 検証方法: ベンチツールとして
hyperfineを使う。コンパイル前には成果物を削除する。10回作業を行わせて統計的な情報を得る - その他のマシンスペック
- CPU Ryzen 7 1700X (OC無し)
以下に各実験を示す。データは最後にまとめて示す。
動画変換
NHKの7時のニュース(M2TS形式、30分程度、3.37GiB)があるのでこれを変換させる。以下のようなコードでffmpegを呼び出した。
#!/usr/bin/env amm @main def main(toCompressFiles: String*) = { val src: String = sourcecode.File() val root = os.Path(src) / os.up for { file <- toCompressFiles } yield { val filePath = root / file val outfile = s"${file}.mp4" val cmd = Seq("ffmpeg", "-y", "-i", file, "-c:v", "h264_nvenc", "-crf", "30", "-b:v", "2000k", "-c:a", "libopus", "-ar", "48000", "-b:a", "128k", "-vf", "scale=1024:-1", "-strict", "-2", outfile) os.proc(cmd).call(cwd = root, stdin = os.Inherit) // TODO: redirect 1>&2 } }
hyperfine "./compress_cuda.scala.sc input.m2ts"
コンパイル
Scala
ScalaのデカいプロジェクトといえばCatsなので、Catsのcoreモジュールをコンパイルさせてどのくらい時間がかかるかを測定した。
hyperfine -p 'sbt clean' 'project core; sbt compile'
C
CのデカいプロジェクトといえばもちろんLinuxなので、Linuxカーネルをコンパイルしてどのくらい時間がかかるかを測定した。Linuxはデカすぎて時間がかかりすぎるので、3回コンパイルしたら良しとする。
# 事前準備 cp /boot/config-6.0.6-1-default .config make localmodconfig
hyperfine -m3 -p 'cp .config ~/cfg; make clean; make distclean; cp ~/cfg .config' 'make -j16'
opensslによる暗号化
dd if=/dev/urandom of=./random_file bs=1024k count=1000 hyperfine 'openssl enc -e -aes256 -out aes.enc -pass pass:password < random_file'
ssdの影響を受けるおそれがあるため、ssd上で実験し、その後はshm上で実行する。
結果
実行時間は以下のような表となった。
command,min,mean,max,std,mhz ffmpeg,118.054,122.239,139.472,6.429,1333 ffmpeg,93.034,95.308,99.301,2.444,2666 ffmpeg,93.150,95.982,100.924,2.143,3200 sbt,133.717,136.315,141.019,2.321,1333 sbt,102.858,104.674,106.283,1.194,2666 sbt,97.440,99.149,101.542,1.522,3200 make,451.031,452.629,454.991,2.088,1333 make,342.210,342.760,343.231,0.515,2666 make,348.518,354.263,357.553,4.992,3200 openssl_ssd,2.644,2.745,2.867,0.070,1333 openssl_ssd,2.763,3.180,3.349,0.160,2666 openssl_ssd,1.929,2.522,2.685,0.223,3200 openssl_mem,1.878,1.943,1.983,0.033,1333 openssl_mem,1.689,1.708,1.748,0.019,2666 openssl_mem,1.659,1.680,1.696,0.012,3200
これだけだと分かりにくいのでグラフも用意した。縦軸は実行時間なので、数字が小さいほど高性能ということである。

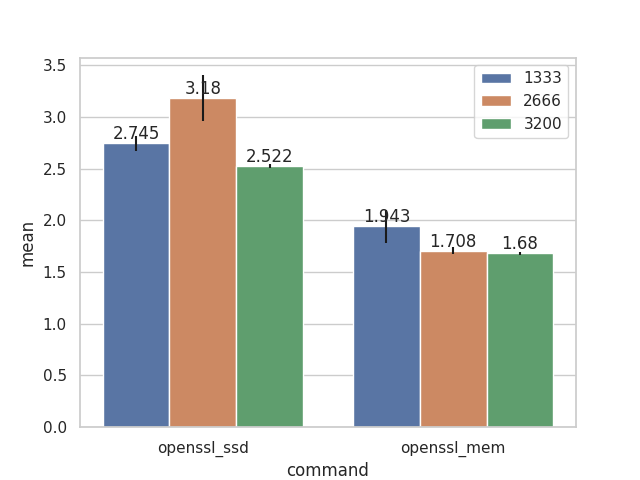
グラフを見ると、以下のようなことが分かってくる:
- 1600MHzから2666MHzにクロックが上がるときは露骨に影響が出た。
- おそらくこの時点ではメモリ速度がボトルネックになっていたと思われる
- 2666MHzから3200MHzにクロックを上げたときはさほど影響が無かった。
- ボトルネックが移動した?
- 多少なりとも速くなったようには見える
- なぜかクロックが上がると速度が落ちた実験もあった
- Linuxコンパイルの実験や、ssd上のopenssl
- 外的要因が存在するのかもしれない?
ちなみに2666MHzから3200MHzに上げたことで数千円メモリのコストが上昇した。この価値に見合う性能増加は全く得られなかったので、次回からは何も考えず標準クロックのメモリを使うことにする。
また、クロックを上げても無意味だということが分かったため、今回交換して余った16GiBのメモリをマザボに戻して48GiBにしようと思う。